| Angjoo Kanazawa* | Jason Y. Zhang* | Panna Felsen* |
|
|
|
| [Paper] |
|
|
|
|
|
|
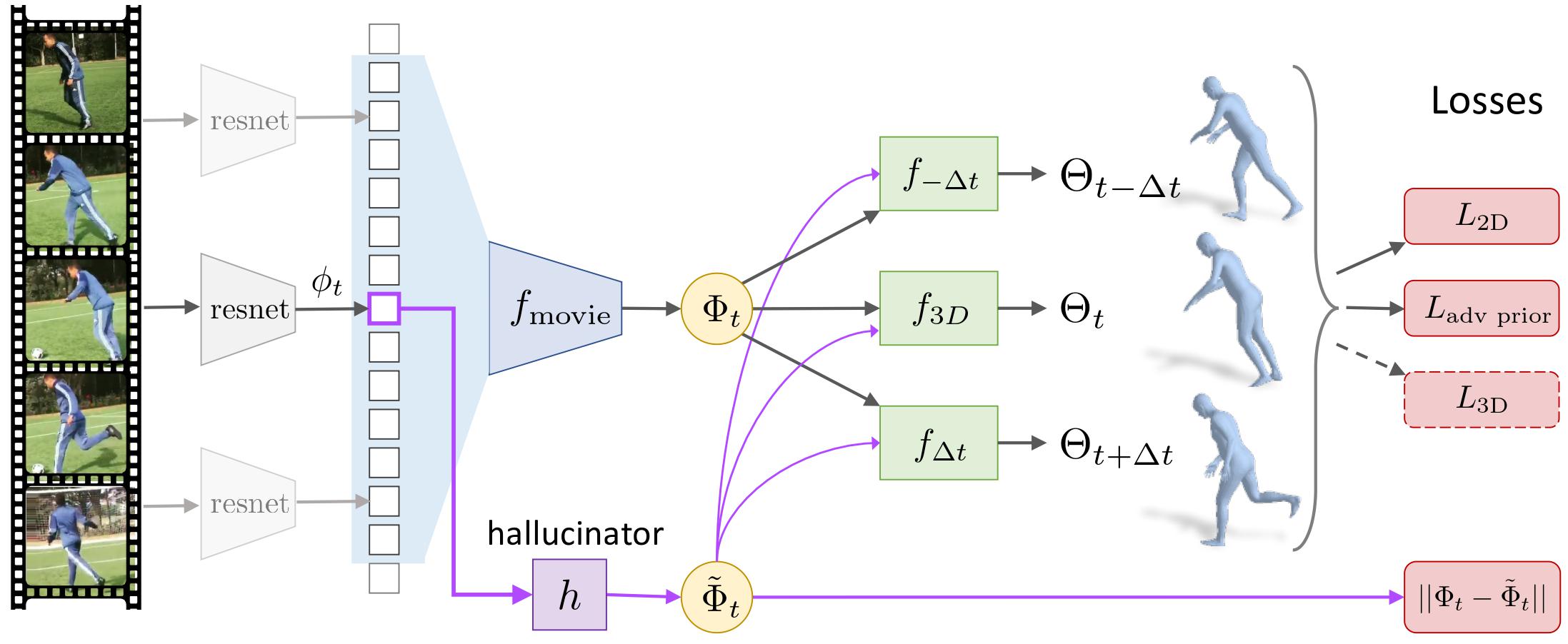
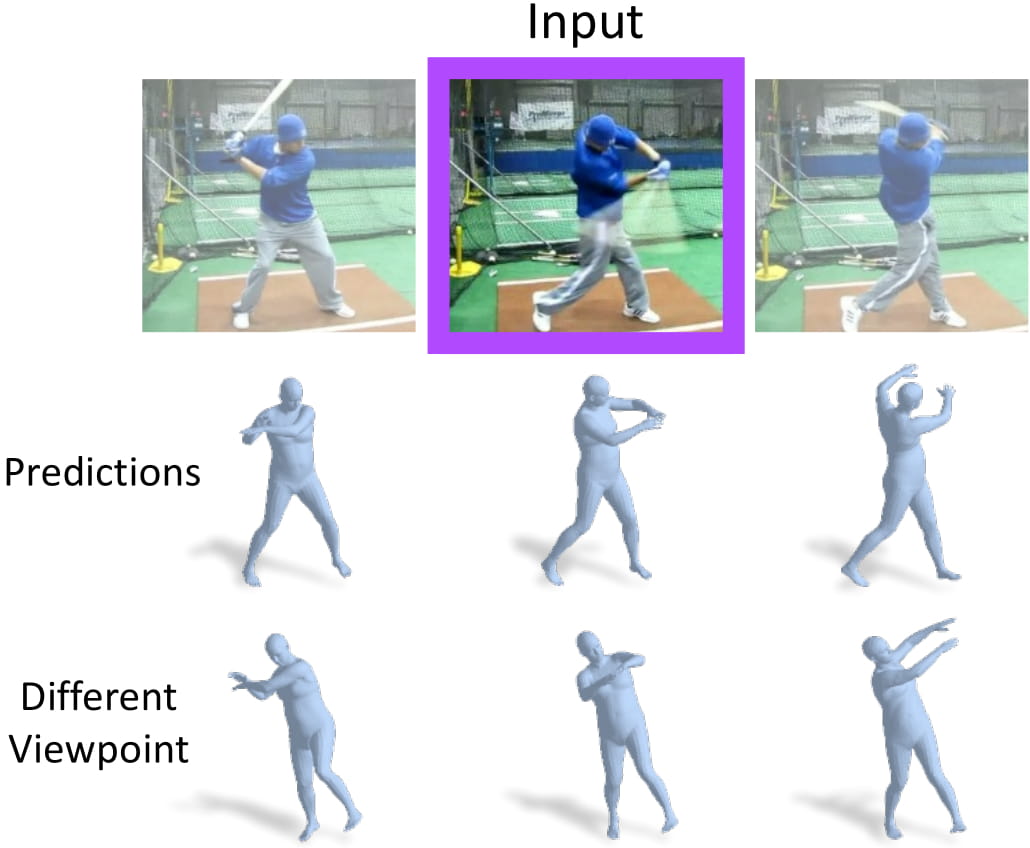
From a single image (purple), our model can recovers the current 3D mesh as well as the past and future 3D poses. |
 |
Kanazawa*, Zhang*, Felsen*, and Malik. Learning 3D Human Dynamics from Video. CVPR 2019. [pdf] [Bibtex] |
|
|
|
|
Acknowledgements |