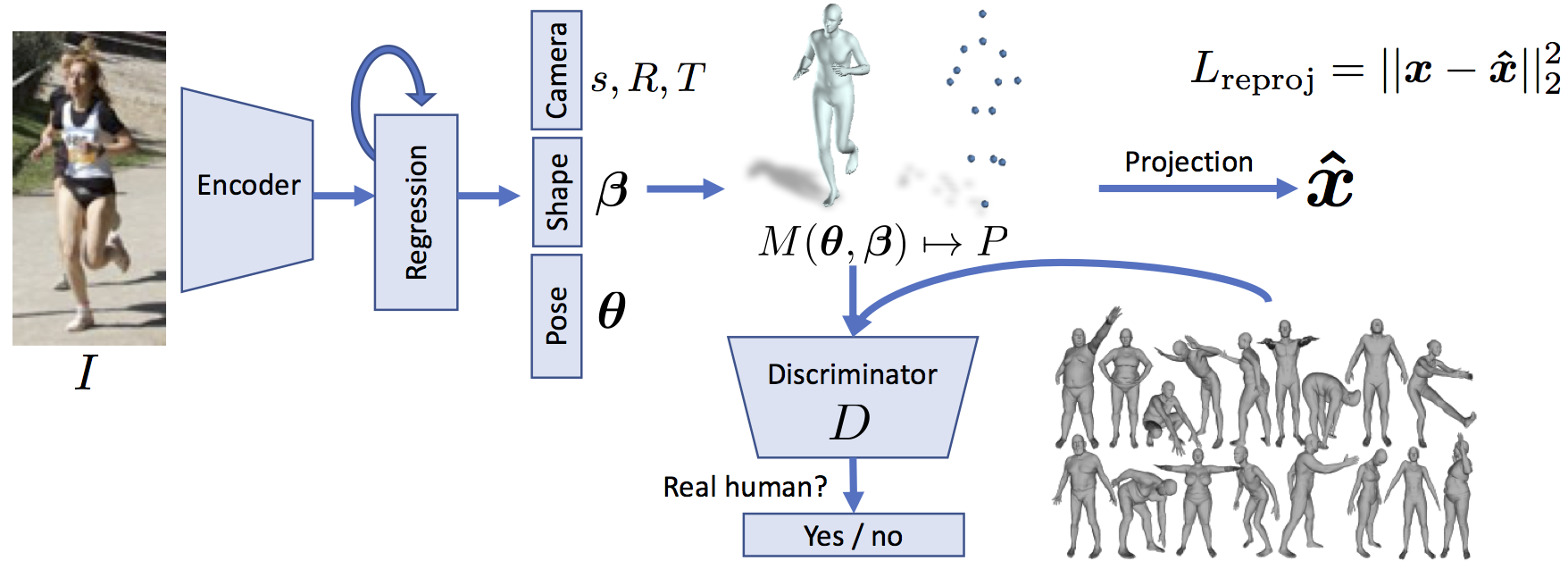
We present an end-to-end framework for recovering a full 3D mesh
of a human body from a single RGB image. We use the generative
human body model
SMPL,
which parameterizes the mesh by 3D joint angles and a
low-dimensional linear shape space.
Estimating a 3D mesh opens the door to a wide range of applications such as foreground and
part segmentation and dense correspondences that are beyond
what is practical with a simple skeleton. The output mesh can be
immediately used by animators, modified, measured, manipulated
and retargeted. Our output is also holistic – we always infer
the full 3D body even in case of occlusions and
truncations.
There are several challenges in training such an model in an end-to-end
manner:
- First is the lack of large-scale ground truth 3D
annotation for in-the-wild images. Existing datasets with
accurate 3D annotations are captured in constrained
environments
(HumanEva
, Human3.6M
, MPI-INF-3DHP
). Models trained on these datasets do not generalize
well to the richness of images in the real world.
- Second is the inherent ambiguities in single-view 2D-to-3D
mapping. Many of these configurations may not be
anthropometrically reasonable, such as impossible joint angles
or extremely skinny bodies. In addition, estimating the camera explicitly introduces an additional scale ambiguity between the size of the person and the camera distance.
In this work we propose a novel approach to mesh reconstruction that
addresses both of these challenges. The key insight is even though
we don't have a large-scale paired 2D-to-3D labels of images in-the-wild, we have
a lot of
unpaired datasets: large-scale 2D keypoint
annotations of in-the-wild images
(
LSP
,
MPII
,
COCO
, etc) and a
separate large-scale dataset of 3D meshes of people with various
poses and shapes from MoCap. Our key contribution is to take
advantage of these
unpaired 2D keypoint annotations and 3D
scans in a conditional generative adversarial manner.
The idea is that, given an image, the network has to infer the 3D
mesh parameters and the camera such that the 3D keypoints match the
annotated 2D keypoints after projection. To deal with ambiguities,
these parameters are sent to a discriminator network, whose task is
to determine if the 3D parameters correspond to bodies of real
humans or not. Hence the network is encouraged to output parameters
on the human manifold and the discriminator acts as a weak
supervision. The network implicitly learns the angle limits for each
joint and is discouraged from making people with unusual body
shapes.
We take advantage of the structure of the body model and propose a
factorized adversarial prior. We show that we can train a model even
without using any paired 2D-to-3D training data (pink meshes are all
results of this unpaired model). Even without using any paired
2D-to-3D supervision, HMR produces reasonable 3D
reconstructions. This is most exciting because it opens up
possibilities for learning 3D from large amounts of 2D data.
Please see
the
paper for
more details.
Concurrent Work
Concurrently and independently from us, a number of groups have
proposed closely related deep learning based approaches for recovering SMPL. Many have a
similar emphasis on resolving the lack of ground truth 3D issue
in interesting and
different ways! Here is a partial list:
- Hsiao-Yu Fish Tung, Hsiao-Wei Tung, Ersin Yumer, Katerina
Fragkiadaki,
NIPS'17. Self-supervised
Learning of Motion Capture
- Jun Kai Vince Tan, Ignas Budvytis, Roberto Cipolla, BMVC'17. Indirect deep structured learning for 3D human body shape and pose prediction
- Georgios Pavlakos, Luyang Zhu, Xiaowei Zhou, Kostas Daniilidis, CVPR'18. Learning to Estimate 3D Human Pose and Shape from a Single Color Image
- Gül Varol, Duygu Ceylan, Bryan Russell, Jimei Yang, Ersin Yumer, Ivan Laptev,
and Cordelia Schmid, ECCV'18. BodyNet: Volumetric Inference of 3D Human Body Shapes
- Mohamed Omran, Christop Lassner, Gerard Pons-Moll, Peter
Gehler, Bernt Schiele, 3DV'18. Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation
SMPL models recovered by any of these approaches could be
improved by using it as an initialization for our optimization
based approach SMPLify proposed in ECCV
2016:
Acknowledgements
We thank Naureen Mahmood for providing MoShed
datasets and mesh retargeting for character animation, Dushyant
Mehta for his assistance on MPI-INF-3DHP, and Shubham Tulsiani,
Abhishek Kar, Saurabh Gupta, David Fouhey and Ziwei Liu for helpful
discussions. This research was supported in part by
BAIR and NSF Award IIS-1526234.
This webpage template is taken
from
humans
working on 3D who borrowed it
from some
colorful folks.