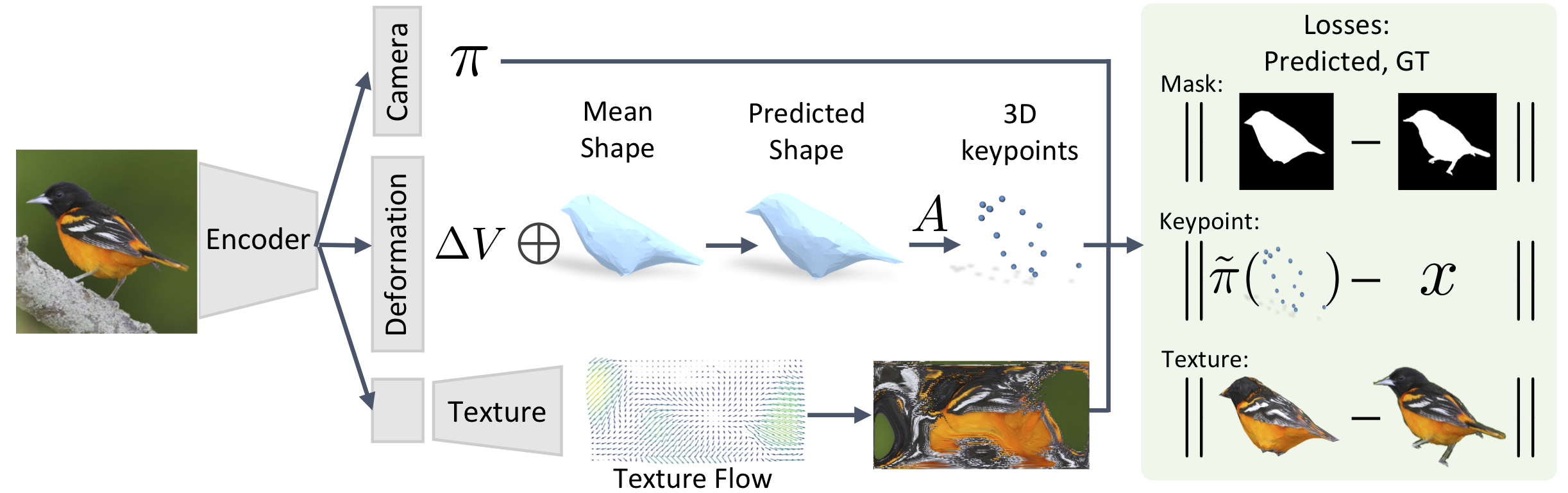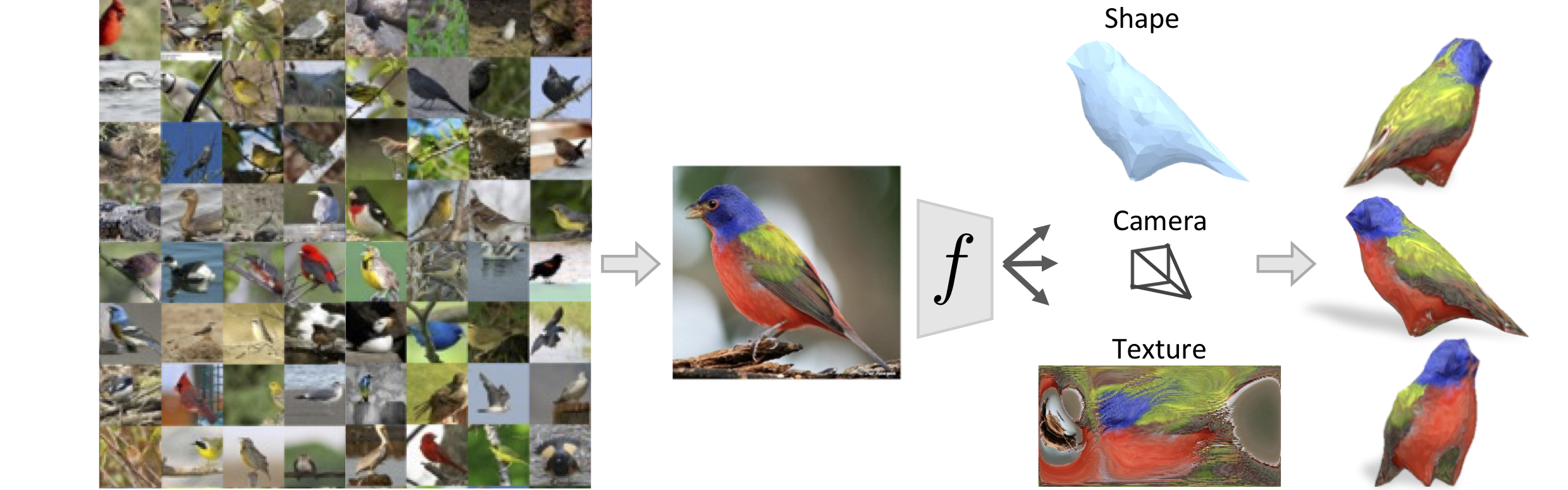
|
|
|
|
|
|
In ECCV, 2018 |
|
|
|
|
|
|
|
 |
Kanazawa, Tulsiani, Efros, Malik. Learning Category-Specific Mesh Reconstruction from Image Collections. In ECCV, 2018. [pdf] [Bibtex] |
|
|
Acknowledgements |